0x00 前言
该文章介绍2016年全国高校密码数学挑战赛的赛题三——RSA加密体制破译真题的相关解法,并提供RSA密文破解的常规思路。文章中提到的所有文件及相关脚本均可以从项目RSA_Breaking中获取。
0x01 对应攻击方法
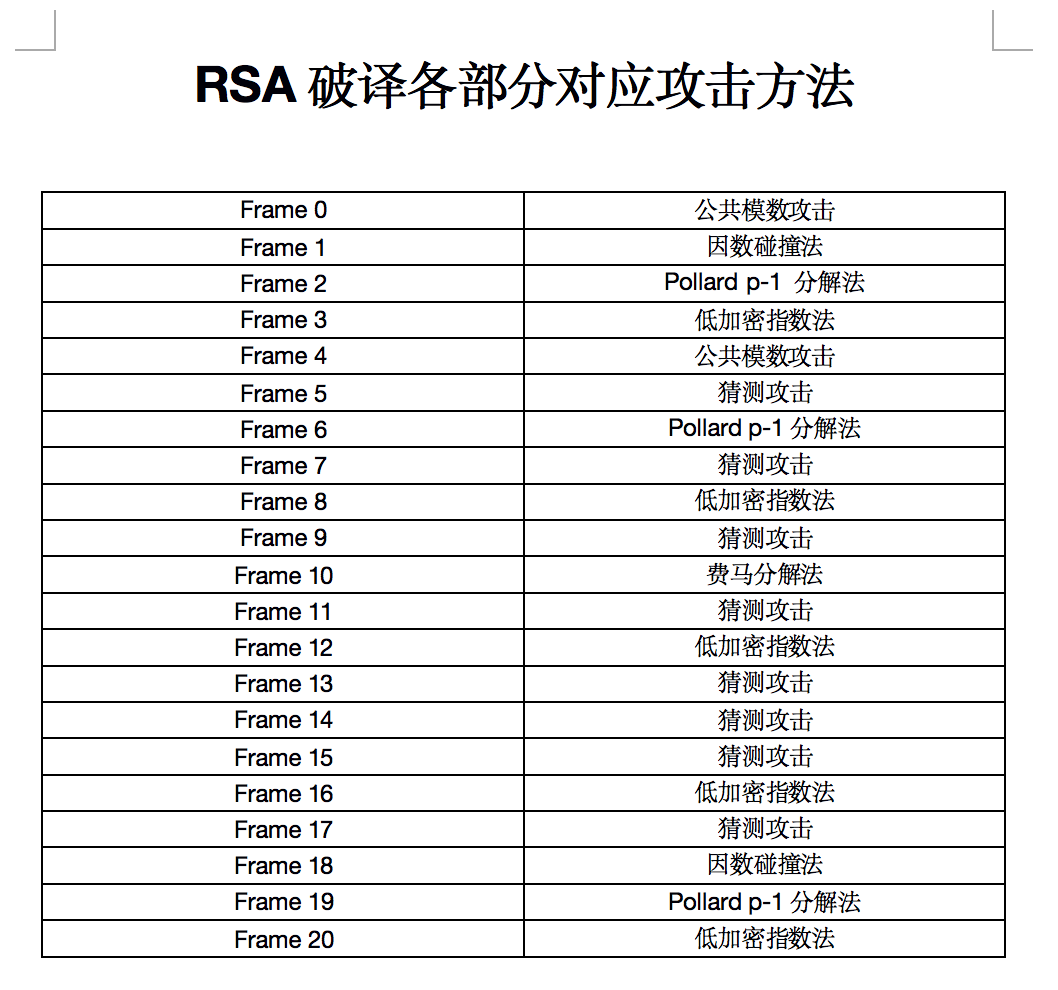
根据上表,我们在破译明文过程中采用了公共模数攻击法、猜测攻击法、Pollard p-1分解法、低加密指数法、费马分解法和因数碰撞法共六种方法。下面进行说明。
0x02 解析密文结构
题目给出了21个明文分片的加密结果。针对任意待加密明文,以8字符为单位长度进行划分,得到的结果随后进行相关填充,注意在填充过程中需要加入通信序号,我们可以通过通信序号进行片段还原。具体填充与加密过程可以参考过程及参数.txt。根据该txt文档,我们对提供的Frame0-Frame20进行密文解析,分离出重要参数模数n,加密指数e和密文c,脚本如下:
1 | for i in range(21): |
对解析得到的参数进行分析,分析方法如下:
- 遍历所有的模数N,判断是否存在模数相同的加密片段
- 遍历寻找任意两个模数N的公因子,如果得到不为1的公因子则可以成功分解这两个模数
- 遍历所有加密指数e,寻找低加密指数及对应的加密对
- 剩下的片段采用费马分解和Pollard p-1分解进行尝试
- 常规方法使用完如果还有剩余片段,可以采用猜测攻击的方法。当然,针对猜测攻击的结果需要进行游程计算,以验证结果的精确性。
经过以上分析,得出结论:
- Frame0和Frame4的模数N相同,假设这两片段对应的明文内容相同,则可以使用公共模数攻击的方法
- Frame1和Frame18的模数N具有公共因子,可以通过因数碰撞法还原明文
- Frame3,Frame8,Frame12,Frame16和Frame20采用低加密指数
e=5进行加密 - Frame7,Frame11,Frame15采用低加密指数
e=3进行加密
0x03 公共模数攻击
攻击原理

函数构建
针对Frame0和Frame4,构建共模攻击函数:
1 | # 欧几里得算法 |
破译结果
1 | # Frame0: My secre |
0x04 因数碰撞攻击
攻击原理
通过爆破的方法,如果发现两个模数N具有公共因子,则可以通过简单的乘除处理进行模数分解,最终破解出这两个模数对应的明文。
函数构建
针对Frame1和Frame18,构造因数碰撞函数:
1 | # 因数碰撞法 |
破译结果
1 | # Frame1: . Imagin |
0x05 低加密指数攻击
攻击原理

函数构建
通过以上原理可以看出,对于低加密指数进行的攻击实质上为爆破攻击,可以通过循环开方的方法进行破解。构造破解函数如下:
1 | # 低加密指数攻击 |
破译结果
1 | # e = 3对应的三段明文还原失败,均为不可识别的乱码,故需要使用其他方法破解Frame7、Frame11和Frame15 |
0x06 费马分解法
攻击原理

函数构建
根据原理构建解密函数如下:
1 | # 定义费马分解法,适用于p,q相近的情况 |
破译结果
爆破运行之后发现Frame10可以被快速解密,结果如下:
1 | # Frame10: will get |
0x07 Pollard p-1分解法
攻击原理

函数构建
根据以上原理,构造Pollard p-1分解函数:
1 | # 定义Pollard p-1分解法,适用于p-1或q-1能够被小素数整除的情况 |
破译结果
使用该函数对所有内容进行爆破处理,发现Frame2,Frame6和Frame19的模数可以使用该方法分解,于是处理后结果如下:
1 | # Frame2: That is |
至此已完成使用常规RSA破解方法对题目的分析,结合所有的明文片段,我们得到现有明文:
1 | Frame0 My secre |
0x08 猜测攻击
结合上述破译结果及通信序号,我们整理之后发现可以连缀成有语义的句子,但部分区域存在空缺。于是使用Google搜索等方法找到原句。填补空缺之后进行相关游程计算。
由于该项目重点在于理清RSA破译思路,故剩余工作不再进行赘述。
0x09 明文结果
经过以上破译工作,明文结果如下:
1 | "My secret is a famous saying of Albert Einstein. That is \"Logic will get you from A to B. Imagination will take you everywhere.\"" |
