0x00 LFSR概述
线性反馈移位寄存器(linear feedback shift register, LFSR)是指,给定前一状态的输出,将该输出的线性函数再用作输入的移位寄存器.异或运算是最常见的单比特线性函数:对寄存器的某些位进行异或操作后作为输入,再对寄存器中的各比特进行整体移位.该结构具有结构简单,运行速度快的特点,常被应用于伪随机数和伪随机噪声的生成中.同时,该原件常与流密码相关部分联合使用.
0x01 LFSR原理
LFSR属于反馈移位寄存器(FSR)的一种,另一种为NFSR.FSR是流密码产生密钥流的一个重要组成部分,在GF(2)上的一个n级FSR通常由n个二元存储器和一个反馈函数组成,如下图所示.
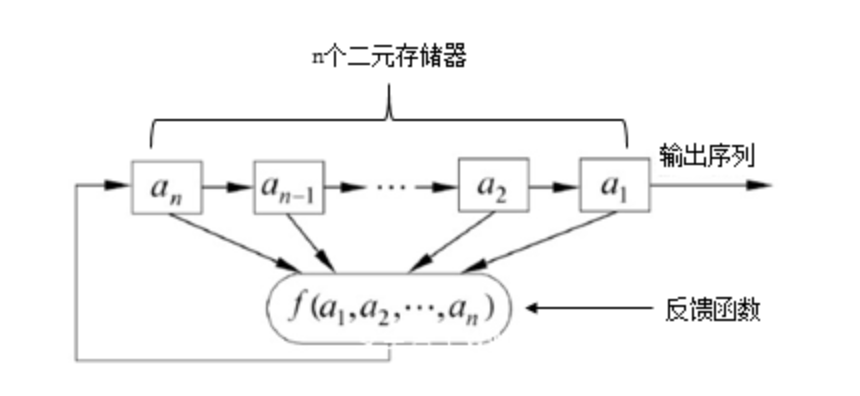
如果这里的反馈函数是线性的,我们则称之为LFSR,此时该反馈函数可以表示为:
其中ci为0/1.我们通过举例来具体说明该过程.
假设给定一个5级LFSR,初始状态为:(a1,a2,a3,a4,a5) = (1,0,0,1,1),反馈函数为:f(a1,a2,a3,a4,a5) = a4 ^ a1.整个过程如下图所示.
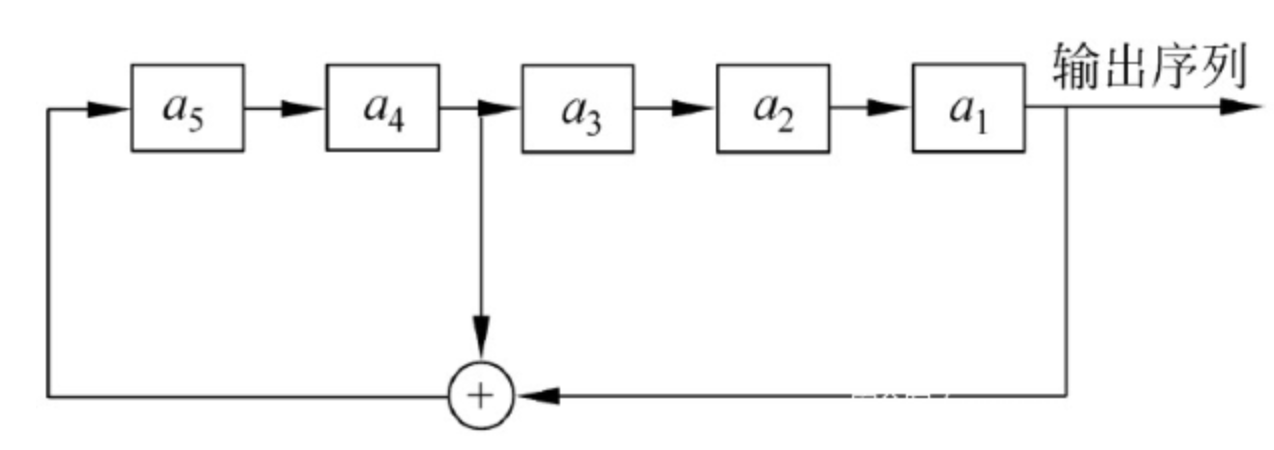
前五位初始状态为10011,则a6 = a4 ^ a1 = 0,a7 = a5 ^ a2 = 1,以此类推我们得到前31位的计算结果如下: 1001101001000010101110110001111.
对于一个n级LFSR来说,其最大周期为2^n-1,对于这里选取的5级LFSR,其最大周期可以确定为31.故产生的随机数为前31位的周期循环.通过这些分析可以发现,对于LFSR系统,我们关心初始状态,反馈函数和输出序列这三个部分,而在CTF题目中经常给出反馈函数和输出序列,将待求的初始状态作为需要提交的flag来设题.
0x03 LFSR在CTF中的应用
本部分来总结CTF中一些比较有趣的LFSR类题目.本篇文章重点介绍已知掩码mask情况下进行的求解.
基础类型
爆破解法
本类题目由于待求的初始状态(即flag)位数较少的情况.由于初始状态下每个位置只有两种可能,所以爆破算法时间复杂度为2的指数级,当位数较少时,可以通过直接爆破的方法得到flag.
典型例题
题目来源: 2018 强网杯 streamgame1
题目说明:
1 | from flag import flag |
爆破关键脚本:
1 | for k in range(2**19): |
分析解法
当初始状态位数过多时,显然直接爆破所需要的成本将大大提高.此时我们需要从原理对题目提供的LFSR进行分析,然后逆向求解.
典型例题
题目来源: 2018 CISCN线上赛 oldstreamgame
题目说明:
1 | flag = "flag{xxxxxxxxxxxxxxxx}" |
题目分析:
本题显然是一个线性反馈移位寄存器的结构,flag为8位十六进制,即32bits,我们可以使用暴力枚举的方法,但最好还是分析一下原理并逆向求解.我们已知输出结果和代码表示的反馈函数,现在只需要还原出原始状态即可.
首先拆解分析lfsr函数.
该函数的输入为8位十六进制初始状态R和已知二进制掩码mask.
output = (R << 1) & 0xffffffff: 取R左移一位后的低32位,将值赋给output;
i = (R & mask) & 0xffffffff: 把传入的R和mask进行按位与运算,结果取低32位并赋于i;
1 | lastbit = 0 |
从i的最低位向最高位依次进行异或运算,将运算结果赋给lastbit变量;
output ^= lasbit: 将output变量的最后一位设置成lastbit变量的值; return (output, lastbit): output为经过一轮lfsr之后的新序列,lastbit为经过一轮lfsr之后的输出.
对于提供的常数mask,只有其第3,5,8,12,20,27,30,32这几位为1,其余位为0.考虑到后面的将i每位进行相互异或这一过程可知,mask为0的位是清零位,输入R中对应位的值不会影响最终结果;而mask为1的位是保持位,输入R对应位的结果不变.从而lastbit = R3 ^ R5 ^ R8 ^ R12 ^ R20 ^ R27 ^ R30 ^ R32,显然R与lasbit之间满足线性关系.
当即将输出第32位lasbit时,R已经左移31位,我们得到以下示意图.
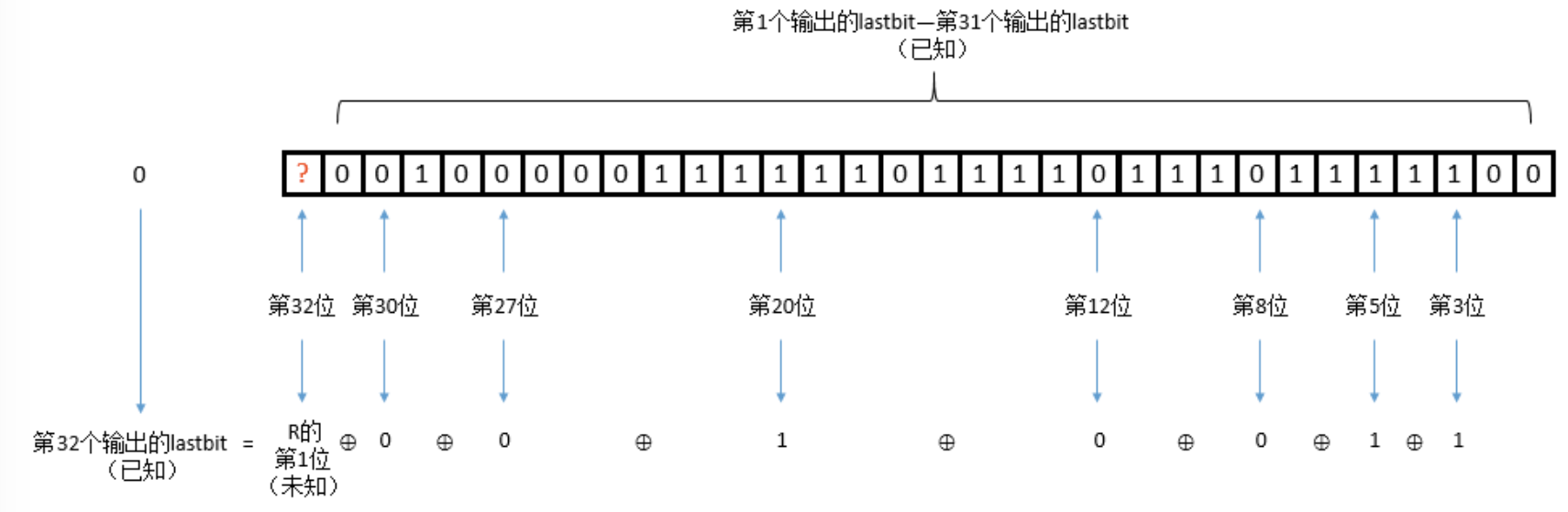
这样我们可以还原出R的第1位,使用同样的方法我们可以得到R的第2位.
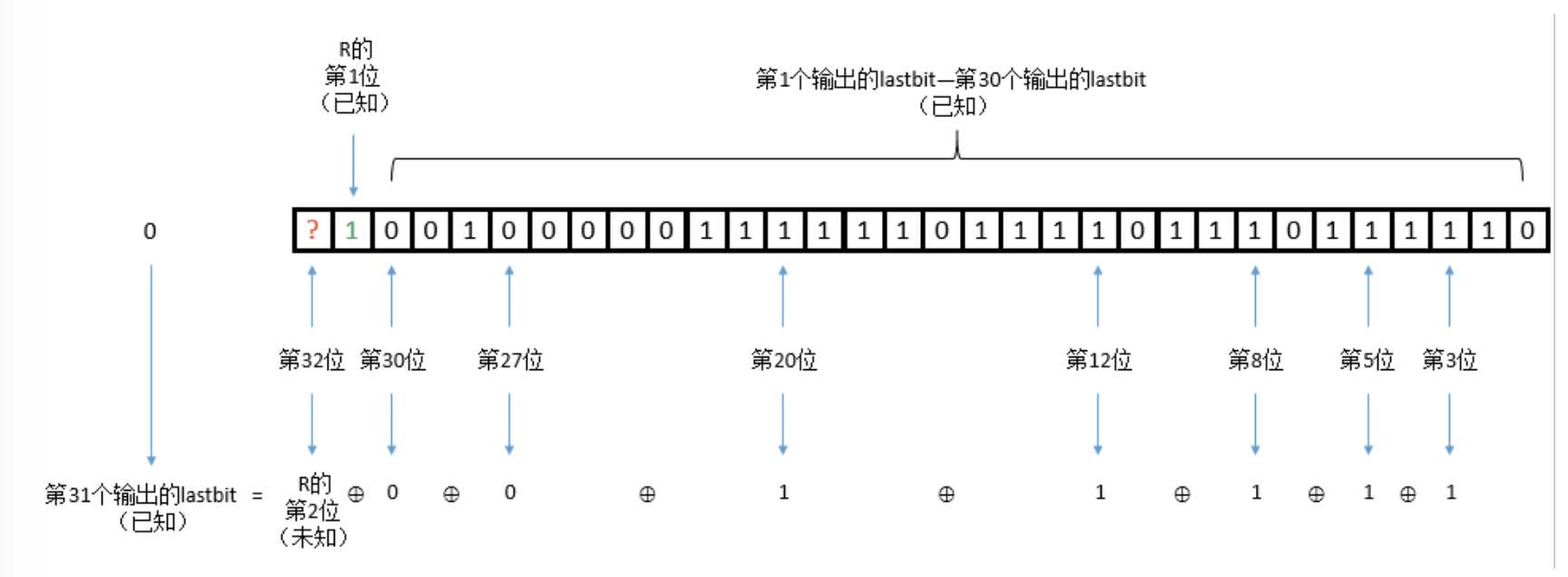
使用此类方法,我们可以实现R的32位全部还原,脚本如下:
1 | mask = '10100100000010000000100010010100' |
类似题目
1 | 2018 强网杯 线上赛 streamgame1 |
分组码基底相关解法
分组码
对每段长度为k的信息,以一定的规则增加r=n-k个校验元,组成长为n的序列,称这个序列为码字.
在GF(2)下,信息组共有2^k个,相应的码字也有2^k个,我们称这2^k个码字的集合为(n,k)分组码.当校验元与信息元之间是线性关系时,我们称之为线性分组码,一般用[n,k]表示.
[n,k]线性分组码是定义在F2上的n维线性空间中的一个k维子空间,由于该线性子空间在加法运算下构成阿贝尔群,所以线性分组码也被称为群码.
[n,k]线性分组码的2^k个码字组成了一个k维子空间,因此这2^k个码字完全可由k个独立矢量所组成的基底张成.我们设基底为:
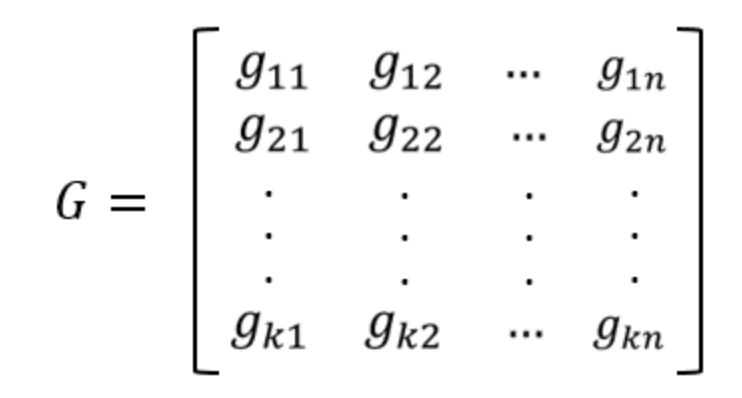
将这组基底写成矩阵形式,则有,
[n,k]码中的任何码字都可以由这组基底的线性组合生成,即:
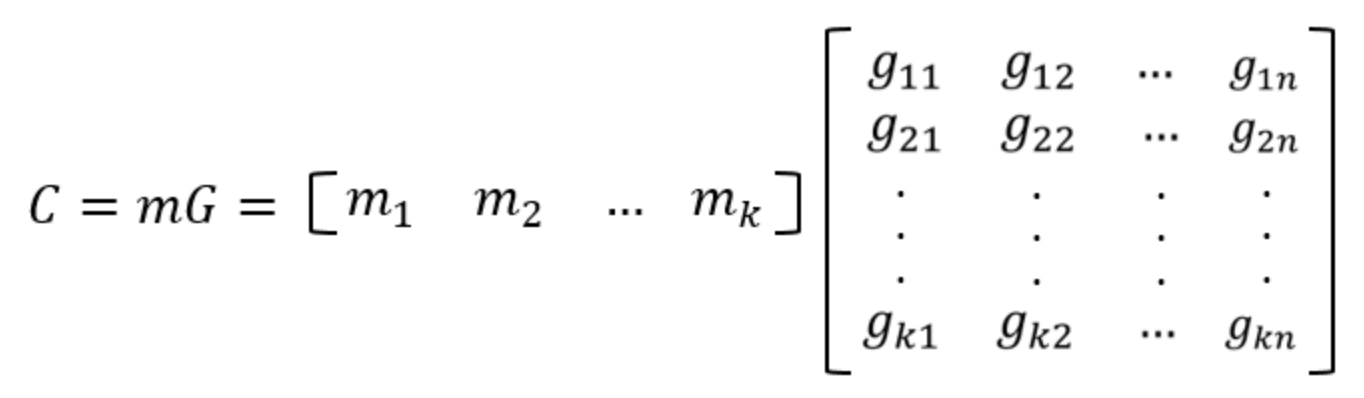
其中,m = (m1,m2,….,mk)是k个信息元组成的信息组.因此若已知信息组m,可通过上式求得对应的码字,称G为[n,k]的生成矩阵.
Fast Correlation Attacks
算法分析
相关攻击correlation
attacks最早由Siegenthaler提出,攻击思路是利用单个LFSR的输出序列和函数运算之后大的LFSR的输出序列之间具有的一定相关性这一特点,来还原LFSR大的初始状态.后来快速相关攻击被提出.参考论文如下:
Fast Correlation Attacks:Method and Countermeasures
该论文中提出两种重要的快速相关攻击方法: 一次通过法和迭代译码法.在论文作者建立的模型之下,当单个LFSR的输出序列和函数运算之后的LFSR输出序列之间的相关性大于0.53时,通常认为满足这类攻击的条件.此类攻击方法有一个特点,即在抽头(影响异或结果的比特位数量,亦即mask中为1的位数)数量较少的时候,作用效果比较明显.
下面根据论文内容对两类算法进行分析.设截取输出序列z的长度为N,抽头数为t,级数为L,LFSR序列的相关概率为q = 1-p
算法A
计算截取序列每比特所需要的平均方程数:
计算截取序列的比特的模二加和原LFSR序列的相应比特的模二加相同的概率s(q, t):
计算在m个方程中至少有h个方程成立的概率Q(q,m,h):
zn = un并且m个方程中至少有h个方程成立的概率为:
在这种条件下,zn = un的概率为:
然后我们求出一个最大的h,并记为hmax,使得如下表达式成立:
计算在L个比特中错误的平均数:
从下式中选取至少满足hmax个校验等式的L个比特:
将z这L个比特作为LFSR输出序列的对应位置的估计I0,由I0可以得到寄存器序列{un}的估计,根据{un}的估计和{zn}的相关性来判断I0是否正确.如果不正确,则对I0依次加上重量为1,2,3…n的向量,得到I0的修正值,重复这一过程,直到找到正确解.
算法B
计算截取序列每比特所需要大的平均方程数:
对{un}的任一比特un均可以得到如下m个校验等式:
其中bi是{un}中t个不同元素的和.把{zn}中对应位置的元素代入上式得:
设yi中t个不同位置的正确概率分别为q1,q2,…,qt,则有:
并且
当zn满足第i1,i2,…,ih校验等式,而不满足j1,j2,…..,jm-h校验等式时,有:
zn至多满足h个校验等式的概率为:
当zn = un,且至多满足h个校验等式的概率为:
当zn != un,且至多满足h个校验等式的概率为:
若zn至多满足h个校验等式,则取补,z中取补元素个数的期望值为:
取补后错误的个数为:
取补后正确的个数为:
取补后正确比特位增加的概率为:
对给定的q、m,找出使得I(q,m,h)最大的h,记为hmax.
若I(q,m,h)<=0,表示该算法没有起到校正作用,算法失败.
若I(q,m,h)>0,则第一次迭代后,有:
- 两算法对比
- 算法A
- 优点: 错误率接近0.75时攻击效果显著.
- 缺点: 当抽头数量较多时,该攻击将逐渐退化为穷举攻击.
- 算法B
- 优点: 错误率接近0.5时攻击效果显著.
- 缺点: 该攻击需要进行大量的双精度计算,计算量较大
- 算法A
攻击工具
开普敦大学于2011年发布如下项目:fast correlation attacks project,该项目中包含了很详细的攻击思想,设计流程和实现方案,我们可以采用该方案来施展一次标准的Fast Correlation Attacks(需要GNU Scientific Library库依赖).编译和报错及提取脚本编写可以参考: 参考文章.
典型题目
题目来源: 2019 0CTF/TCTF 线上赛 zero0lfsr
题目说明:
1 | from secret import init1,init2,init3,FLAG |
题目分析:
观察该题目所给出的加密脚本,我们可以看到,lfsr部分虽然是以class的形式给出,但由于给出的反馈函数形式相同,可以用与上文类似的方法进行分析.观察3个mask不难发现,每个mask只有2位为1,其余部分全为0,于是我们可以得出:
1 | l1.next() = init1[48] xor init1[23] |
到目前为止的分析和上面提及的相差无几,如果给出三组特定的输出序列,我们就可以采用上面的方法进行序列还原,从而得到flag.但这道题目显然没有给出每个初始状态独立的初始序列,而是对输出进行如下混合运算:b = (b<<1) + combine(l1.next(), l2.next(), l3.next()).该函数的返回结果为:(x1*x2)^(x2*x3)^(X1*x3),由于x1,x2,x3均为GF(2)上的数字,因此该表达式则等价为:(x1&x2)^(x2&x3)^(x1&x3).
下面对该函数进行分析,首先对x1,x2,x3及combine()函数的所有返回结果进行穷举:
1 | x1 = 0, x2 = 0, x3 = 0 ——> result = 0 |
观察结果可以发现,当x1=0时,对应的4个result值其中3个为0,1个为1,即x1和result相同的概率为0.75,同理x2和x3也满足这个规律.于是我们发现单个x的值和combine之后的值相同的概率为0.75,从而我们可以考虑上文提到的快速相关攻击,通过概率预测筛选逼近的方法还原最终的output1,output2,output3.
完成对output的提取分离之后,我们按照常规方法还原出各自的init后,按照题目要求拼接计算哈希值,即可得到flag.相关解题脚本如下:
1 | from Crypto.Util.number import long_to_bytes |
上面提及的是一种需要运用数理知识(即快速相关攻击)的解法,下面介绍一种使用z3-solver库进行的爆破解法.
z3约束器根据题目提供的或挖掘出的方程约束来列方程和解方程.值得注意的是,对于正确约束的方程,z3约束器在求解过程中只会返回一组解,但这组解不一定是正确解,此时就需要我们继续为方程组添加约束条件,从而得到精确结果.
解题脚本如下:
1 | #!/usr/bin/env python2 |
结合脚本简单说明几点.
- 对于z3约束器,常用数据类型有Int和BitVec两种.对于需要进行与或非和同异或等比特位之间操作的函数,我们使用BitVec数据类型进行初始化.其他的函数可以使用Int数据类型初始化.
- 建立解题Solver并添加约束,最后使用check函数和model函数输出解题结果.在添加约束方程过程中,按理来说一共有
len(outputs)个方程,不过如果全部添加至约束器中会导致求解速度较慢,经过反复试验得出添加方程数量为200时,既可以保证解的唯一性,又可以在较短的理论实践内求解. - 在
class lfsr()内进行了修改,初始化过程中添加代码self.length = length,这是因为next()函数中使用while i != 0来控制循环,且i = self.init&self.mask&self.lengthmask,在z3求解过程中,init是以未知数的形式传进去的,无法当作具体数值进行判断从而停止循环.于是我们定义与init长度相等的参数,控制直接循环length次.z3待求解的未知数无法作为确定数字参与比较,这也是z3的一个特性,例如如下代码是不合法的:
1 | init = BitVec('init', 48) |
在编写脚本过程中出现了一个非常有意思的编码问题.加密程序的最后部分代码段显示,程序执行了8192次循环,每次循环写入1字节,但最后keystream文件并不是8192字节,而是11990字节.这就涉及到编码问题.加密过程中并不是使用f.write(chr(b))来进行文件写入,而是使用了f.write(chr(b)).encode(),这就造成了长度的实际值与理论值不同.
在python2下,当使用chr().encode()操作大于127的数字时,程序会报错;而在python3中,程序会选择使用2个字节进行表示而不是报错.当数字小于等于127时,python2和python3下都可以正常的使用1个字节表示.该编码过程采用如下规则:
1 | # 在区间[128, 192)内,数字的表示形式会加上xc2前缀: |
了解编码规则之后我们可以进行还原.
1 | # python3 环境 |
0x04 总结
LFSR这一组件有三个关键点:初始状态,反馈函数和输出序列.因此题目的设置也围绕这三个关键点进行.已知mask的情况相当于明确反馈函数,这种情况的题目一般会在输出序列上做文章:简单的题目会直接给出单个LFSR的输出序列,复杂一些的则对多个LFSR的输出序列进行函数操作并最终给出输出结果.
