0x00 引例
From : Problem Address
题目描述: 该题目给出来一长串密文,现在已知该密文是由明文按密钥长度分组后与同一密钥进行异或得到的,需要从密文还原得到明文.
类型: 流密码密钥重用.
0x01 汉明距离
所谓汉明距离,是在二进制层面观测两个等长字符串的比特位差异,比如:
1 | hamming("1010","1011") == 1 |
可见,1010与1011有一个比特位存在差异,所以汉明距离为1.对于两个比特串,有一个快速的方法求解汉明距离:根据0 xor 1 == 1 和 0 xor 0 == 0,可以将两个比特串进行异或然后计算值为1的比特位的个数,就是最后的汉明距离.
简单实现代码:
hamming_distance = bint(bytes1 ^ bytes2).count("1")
汉明距离可以应用于数据相似度的量化,面部识别以及指纹识别等特征数据识别都可以运用到汉明距离来进行数据量化.
Leetcode刷题:
0x02 攻击细节
对于此类流密码重用的题目,我们首先明确思路:第一步,找到进行加密的密钥长度;第二步,通过特定的方法还原出密钥内容;第三步,通过异或得到明文.
下面我们分别进行分析.
0x03 寻找密钥长度
我们首先想到使用爆破来求解密钥长度,但发现随着密钥长度的增加,暴力破解的方法效率十分低下,于是出现了使用汉明距离来求解的方法.具体的汉明距离求解代码如下:
1 | def bxor(a,b): #取字符串等长部分进行异或 |
通过扩展资料,我们可以知道,两个以ascii编码的英文字符的汉明距离是2-3之间,也就是说正常英文字母的平均汉明距离为2-3(每比特),任意字符(非纯字母)的两两汉明距离平均为4.另外,正确分组的密文和密文之间的汉明距离等于对应明文与明文之间的汉明距离.这样,当使用正确的密钥长度后,两两字母进行计算汉明距离,那么这个值应该是趋于最小.我们前几对分组取出计算平均汉明距离,将结果列出.
1 | import base64 |
结果如下:
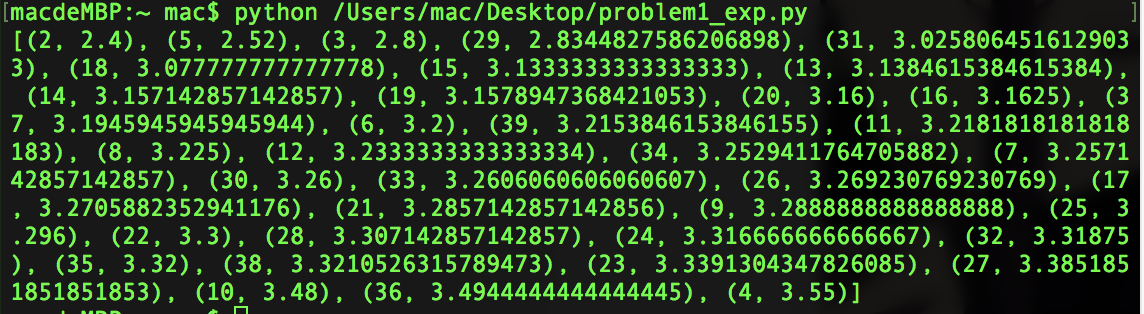
计算出汉明距离后我们可以取前几个密钥长度来进行爆破求解,缩小爆破范围,提高效率.
0x04 爆破得到密钥
密钥获得过程中,有两个行之有效的方法.
Method 1 利用明文空格
我们使用了异或的定律和一个技巧:
1 | 异或定律: c1 xor c2 == p1 xor p2 (p1 = c1 xor K, p2 = c2 xor K) |
该技巧可以使用以下的脚本进行验证:
1 | value = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' |
这样当两个密文按照字节异或后的结果处于字母表的ascii值之间,有很大的概率对应相异或的明文之一为空格,那么根据这个规律,我们可以依次遍历出密钥的每个字节,当捕获的密文组足够多的时候,我们有很大概率得到每个密钥对应异或的字节上的明文为空格,然后依次异或出密钥.
当然,这里有一个问题,如果说两个字母相异或是否也有可能产生ascii码范围内的字符呢?答案是可能的,但是如果一个字符和某一分组中所有的密文相异或的结果都是ascii码字符,我们可以判断该字符一定是空格.
这样我们的任务就非常简单了,将按照爆破的密钥长度进行分组后,每一组对应位置的字符进行重组分组,保证新形成的组别中所有的字符都是对应明文与同一个密钥字符异或的结果.接下来,我们的任务就变成了在新组别中找到明文为空格的位置,我们使用循环嵌套,将新组别中的每一个字符与该组中其他字符异或,结果中含有最多ascii码范围内字符的原始字符最有可能为空格,记录该位置,将该位置对应的密文与空格进行异或,从而得到密钥.
关键部分的证明:
1 | since c1 xor c2 == p1 xor p2 and p1 == c1 xor k,p2 == c2 xor k. |
以下是具体步骤:
1 | 1. 使用取模运算把密文分成n个分组(其中n是密钥长度),如此以来,我们就有了n个独立的凯撒加密式的密文组(因为每个分组里面的值是使用同一个密钥字节明文异或)。这样就把问题简化成了破解n个独立的凯撒加密模式的单字节抑或密码方式。这一步可以直接使用爆破,但是效率不高。我们采取另一种姿势。 |
使用汉明距离的改进版破解代码(KEYSIZE不需要从2开始一直爆破到40,而是只取汉明距离最小的前5种情况)如下:
1 | import base64 |
我们发现,输出结果中,当KEYSIZE为29时,破解出的文字为有意义的英文文本即明文.
Method 2 字频分析
我们可以使用字频来进行分析,即利用字母出现频率的统计规律进行权重赋值,当总权重最高时,我们有理由相信这时的密钥字节是正确的.先贴上解题代码:
1 | import base64 |
0x05 总结
关键词:汉明距离,流密码重用的不安全性.
汉明距离用于判断数据的相似程度,可以通过简单的异或并统计”1”的个数来计算.
异或加密中,明文和明文的异或等于密文和密文的异或,并且二者的汉明距离一样.
空格(0x20)和所有小写字母异或结果为相应的大写字母,和所有大写字母异或的结果为相应的小写字母.
两个以ascii编码的英文字符的汉明距离是2-3之间,也就是说正常英文字母的平均汉明距离为2-3(每比特),任意字符(非纯字母)的两两汉明距离平均为4.
破解此类问题的方法:爆破密钥长度;分组与空格异或寻找密钥;将密钥与密文异或还原明文.其中运用汉明距离可以缩小爆破范围,提高运算效率.
